以下是本计算机毕业源码设计介绍,若对此项目感兴趣,请联系QQ:254540457 
开发环境:Python3.7 + Scrapy框架 + Django网站 + mysql数据库
这个项目有2个爬虫程序和一个网站程序:其中一个爬虫负责分页抓取json格式的数据,分析拿到豆瓣电影的详情页面url地址存入到redis数据库的content_urls集合中;另外一个爬虫负责抓取详情页url的电影内容字段,包括了电影名称、导演、主演、编剧、电影类型、国家、语言、上映日期、豆瓣评分、电影简介等,然后将爬取的电影记录插入到mysql数据库表中;然后一个基于Django框架开发的网站负责电影信息的查询展示,也可以用户注册登录发布留言,还可以查看管理员发布的新闻公告等!
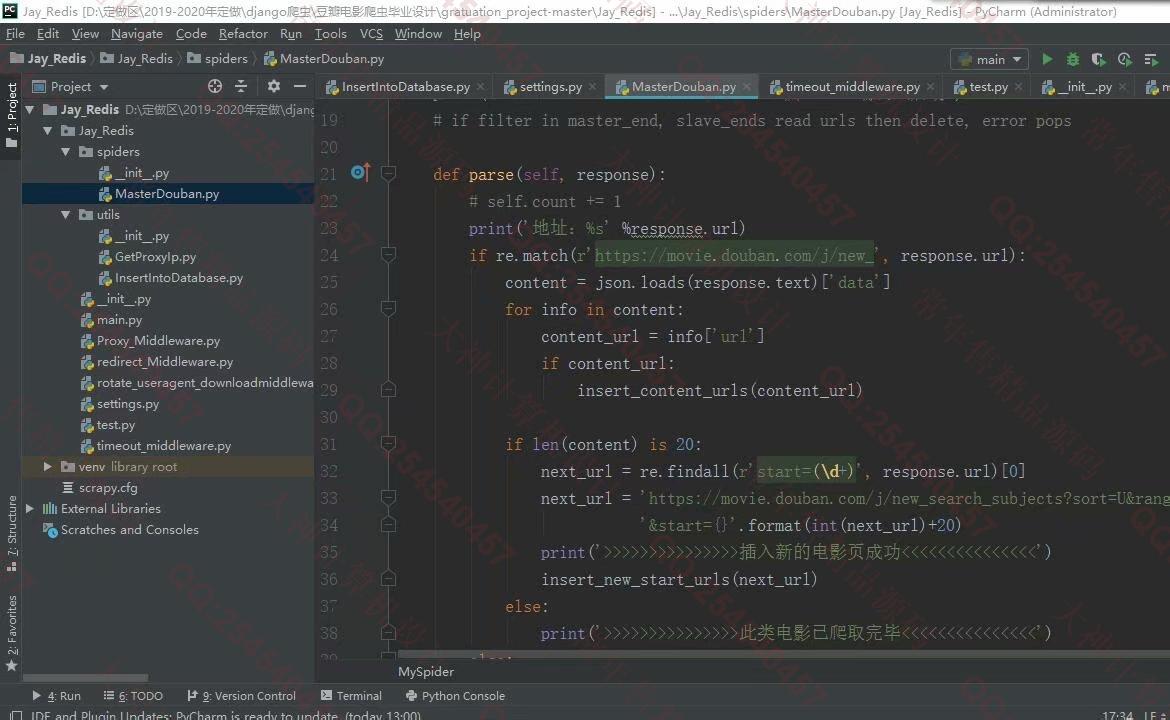
照片名称:1爬豆瓣电影详情地址爬虫源码
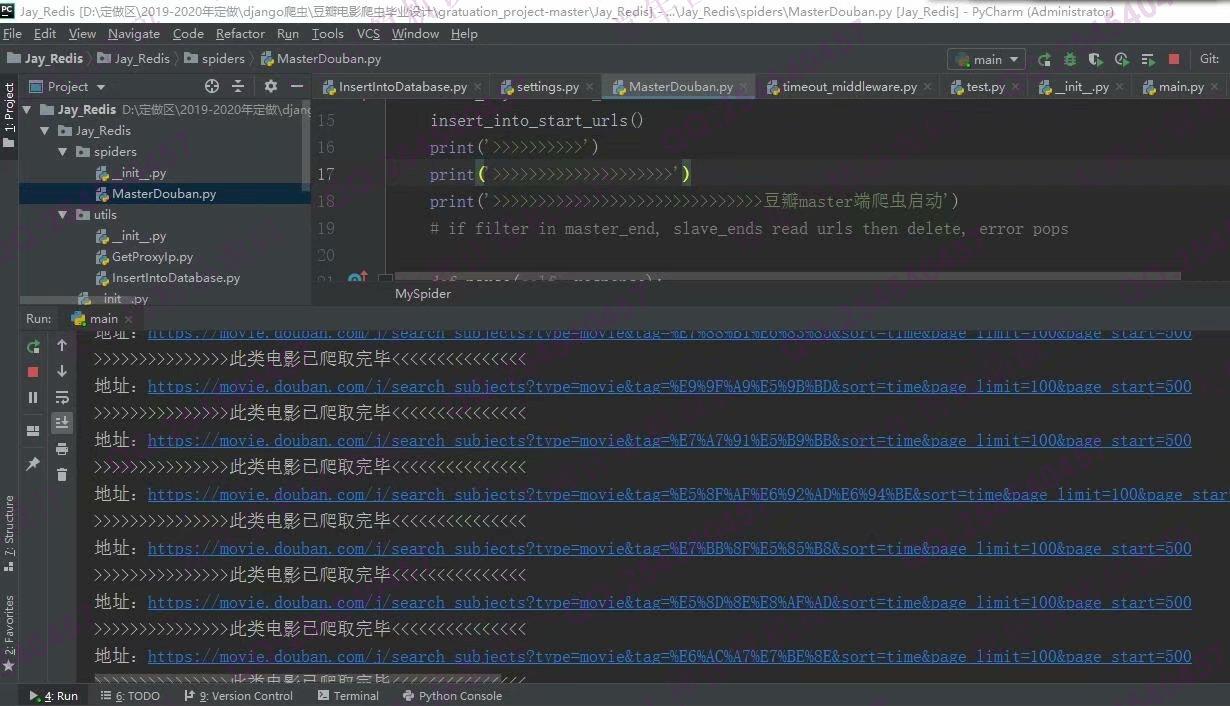
照片名称:2爬详情页地址运行效果图
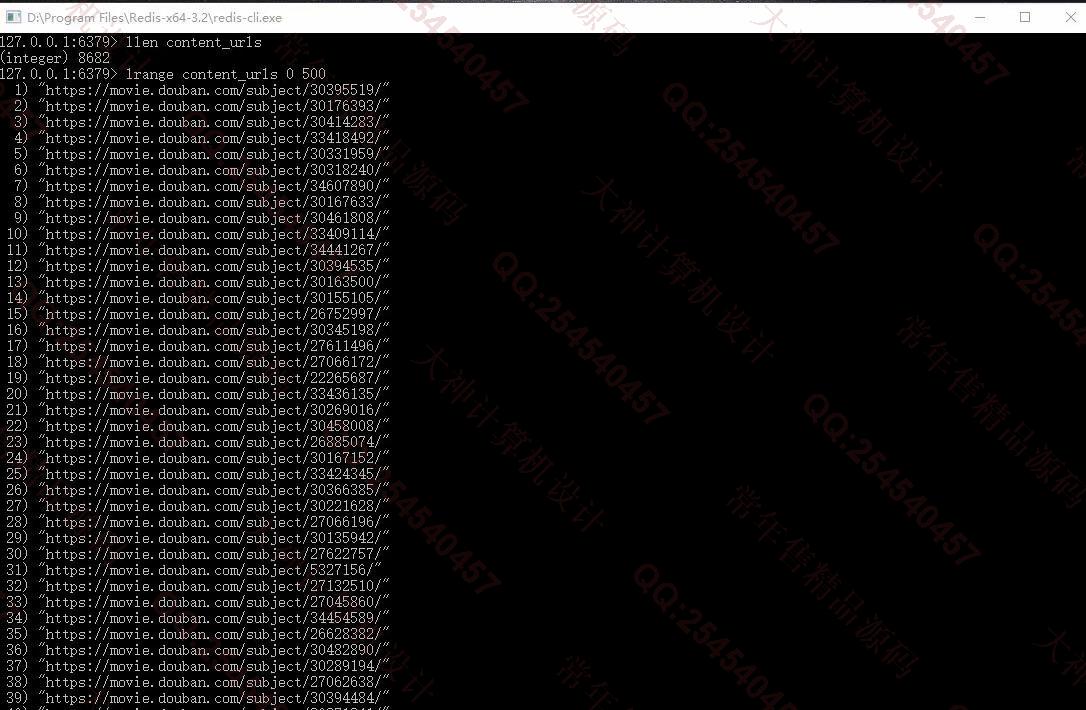
照片名称:3豆瓣电影详情页地址爬取结果
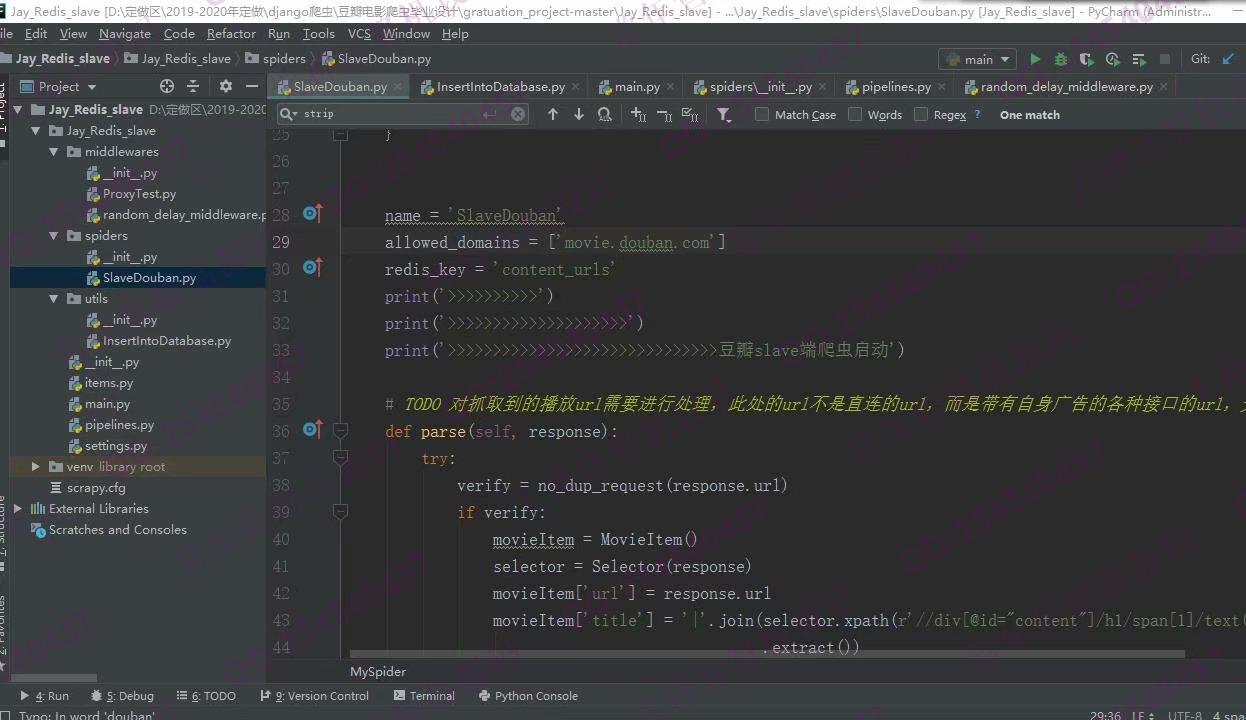
照片名称:4爬取豆瓣电影详情页内容爬虫源码
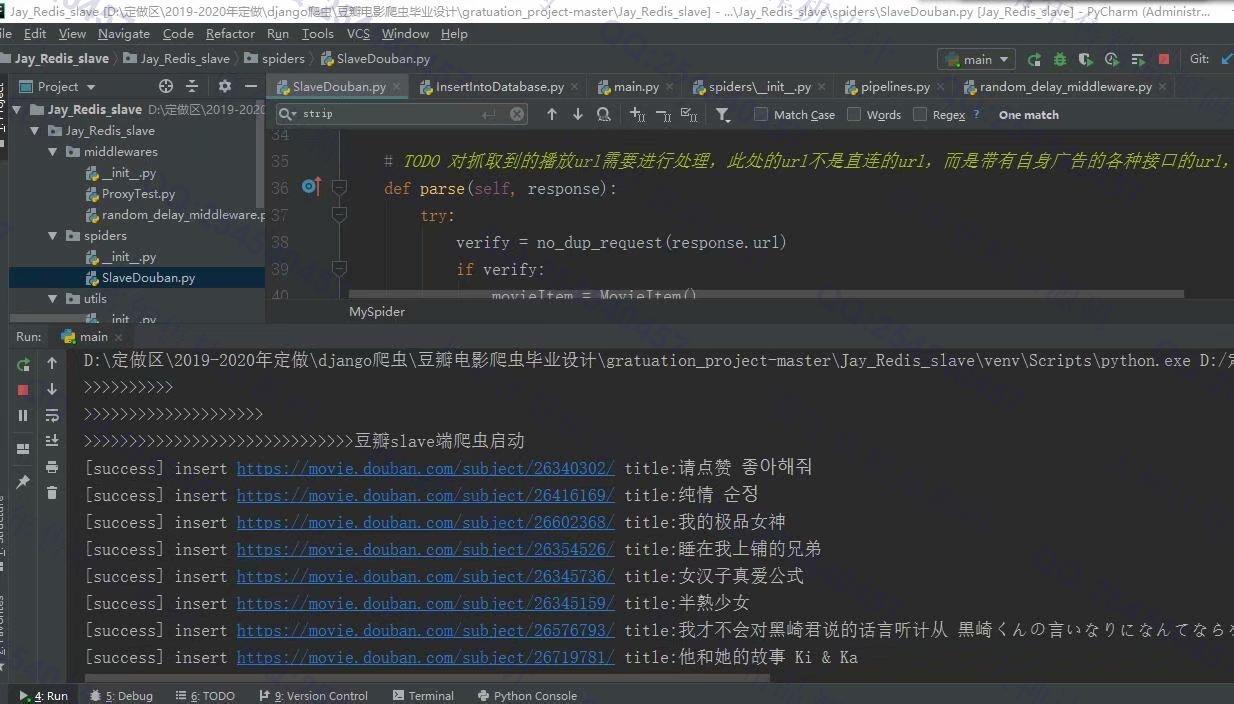
照片名称:5爬取豆瓣电影详情页内容入mysql数据库
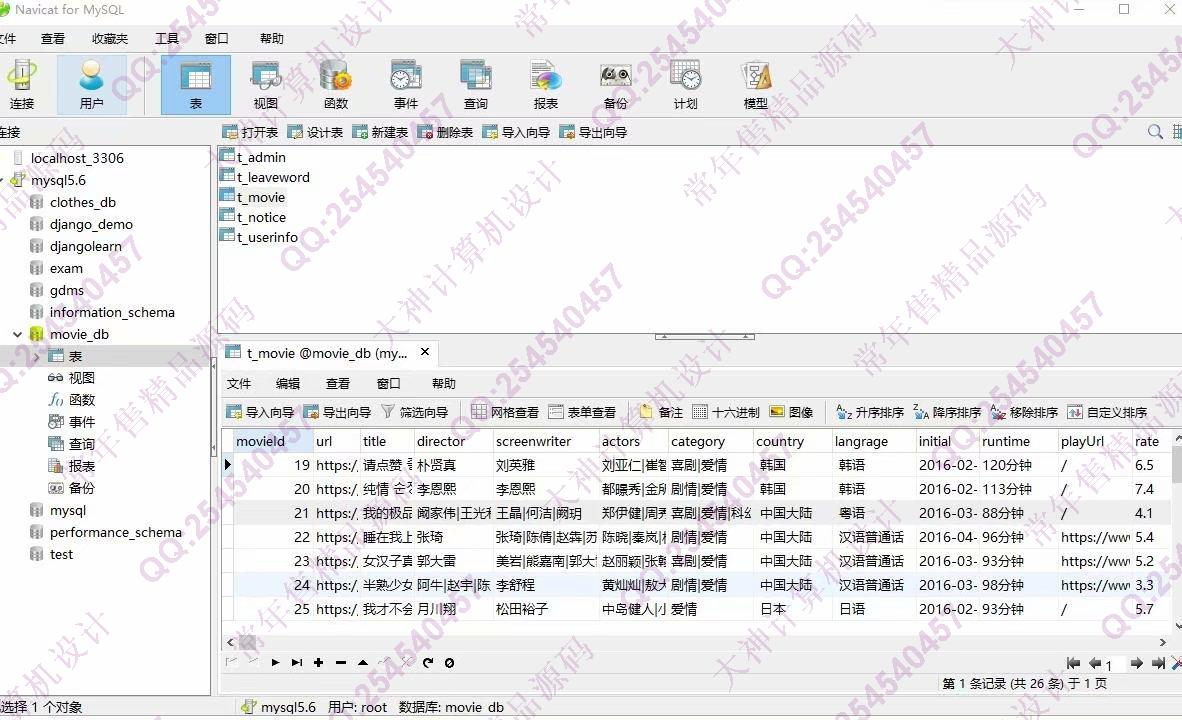
照片名称:6豆瓣电影爬虫到mysql数据效果
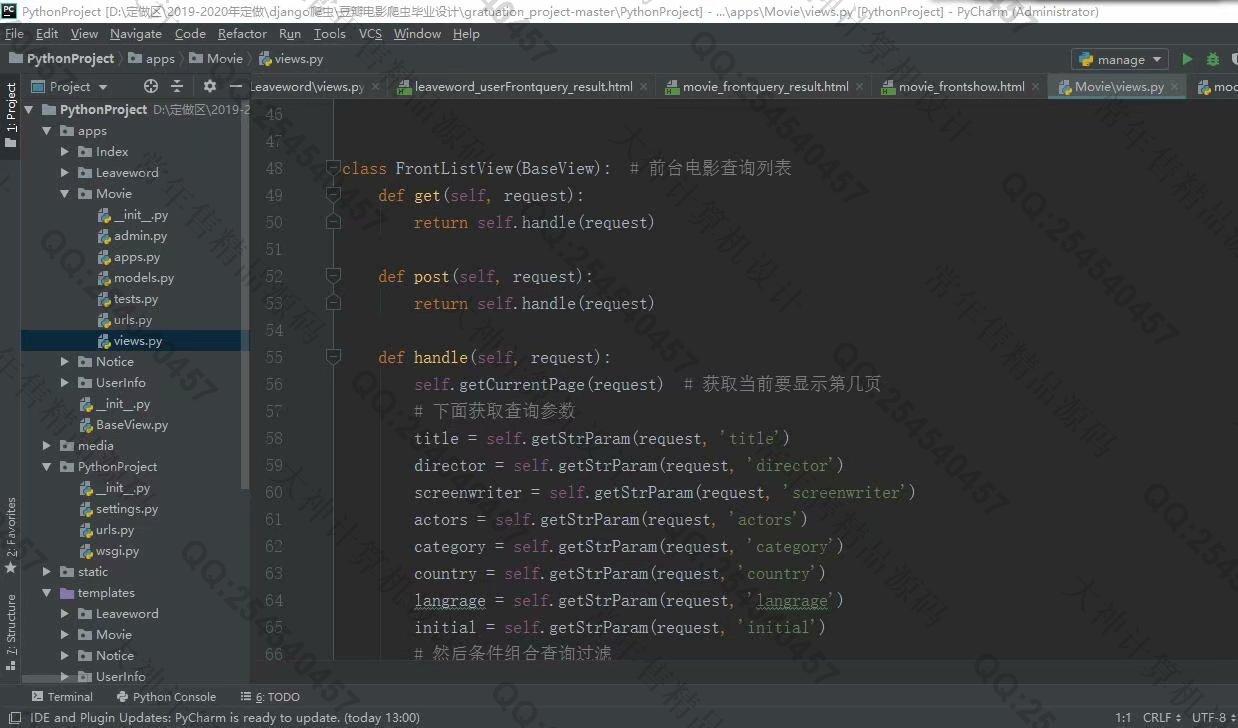
照片名称:7展示电影数据的Django网站源码
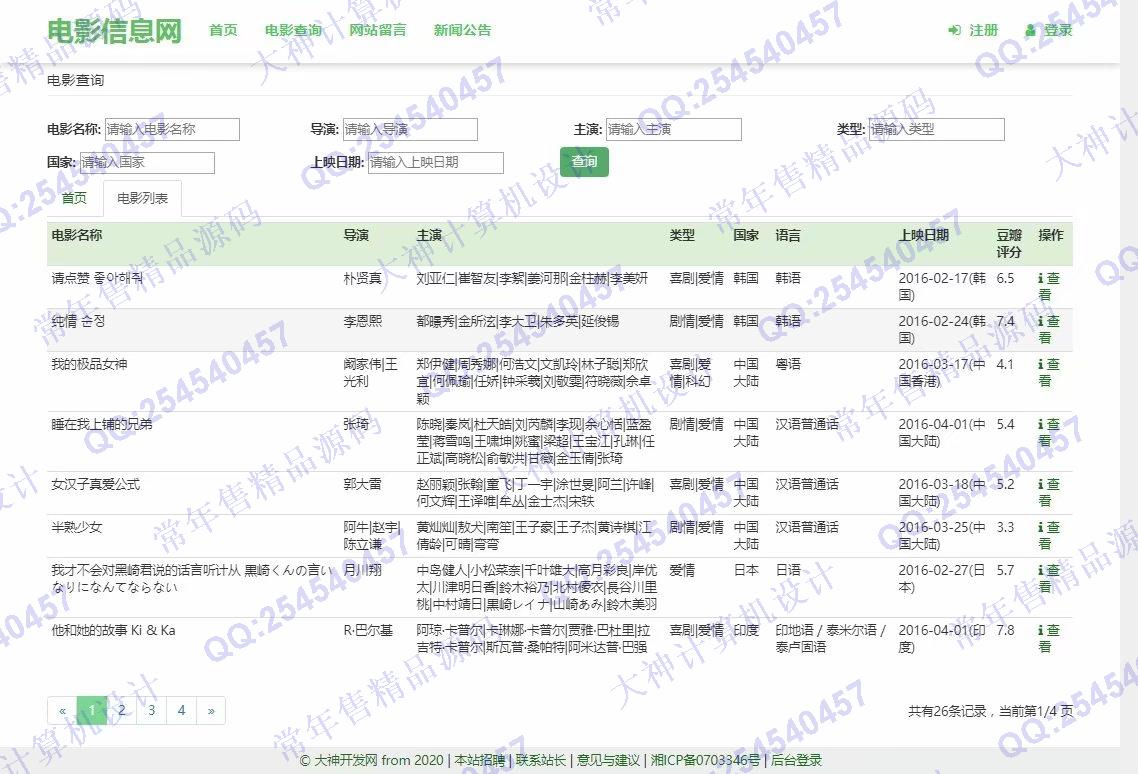
照片名称:8Django网站展示电影数据效果
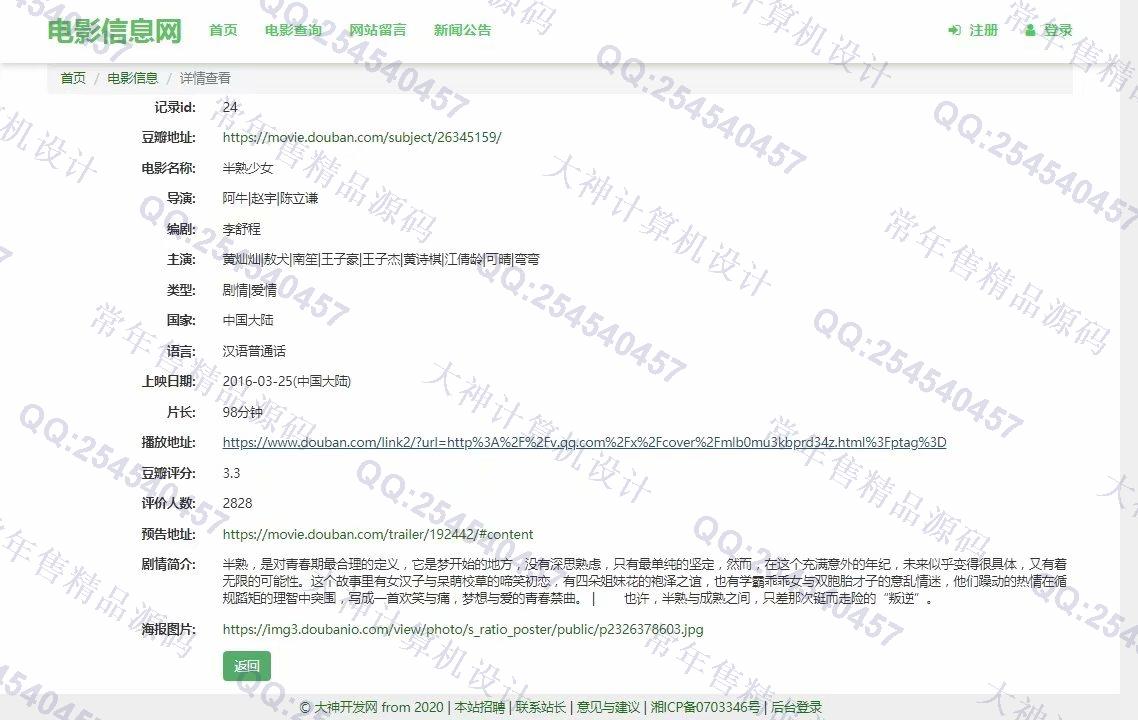
照片名称:9查看电影信息详情
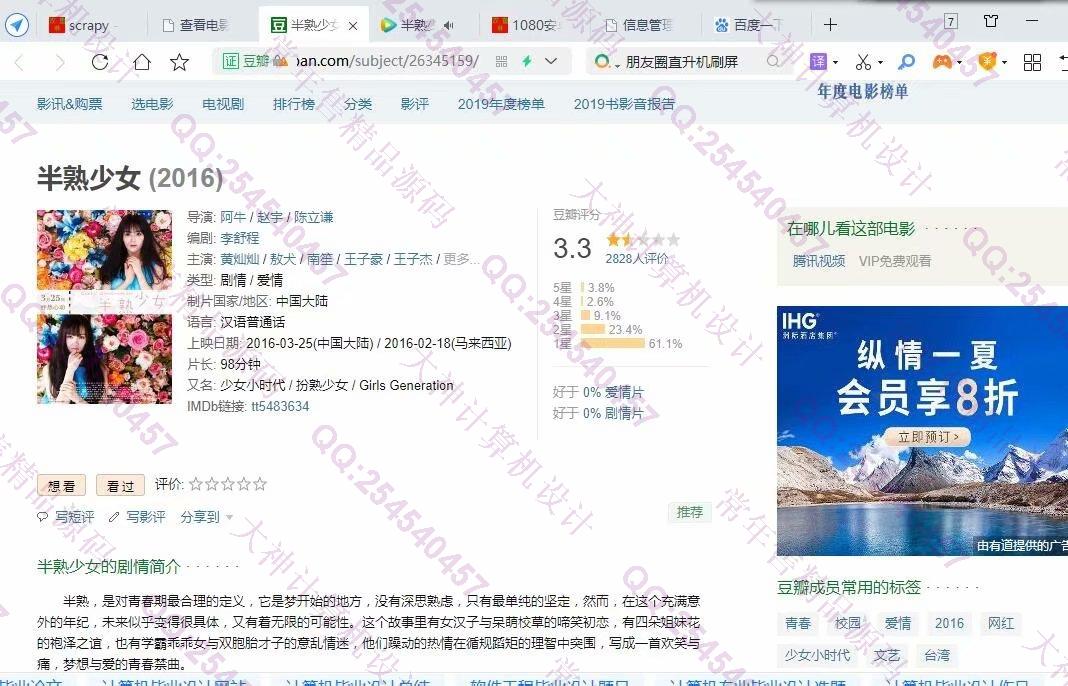
照片名称:10打开豆瓣电影页面
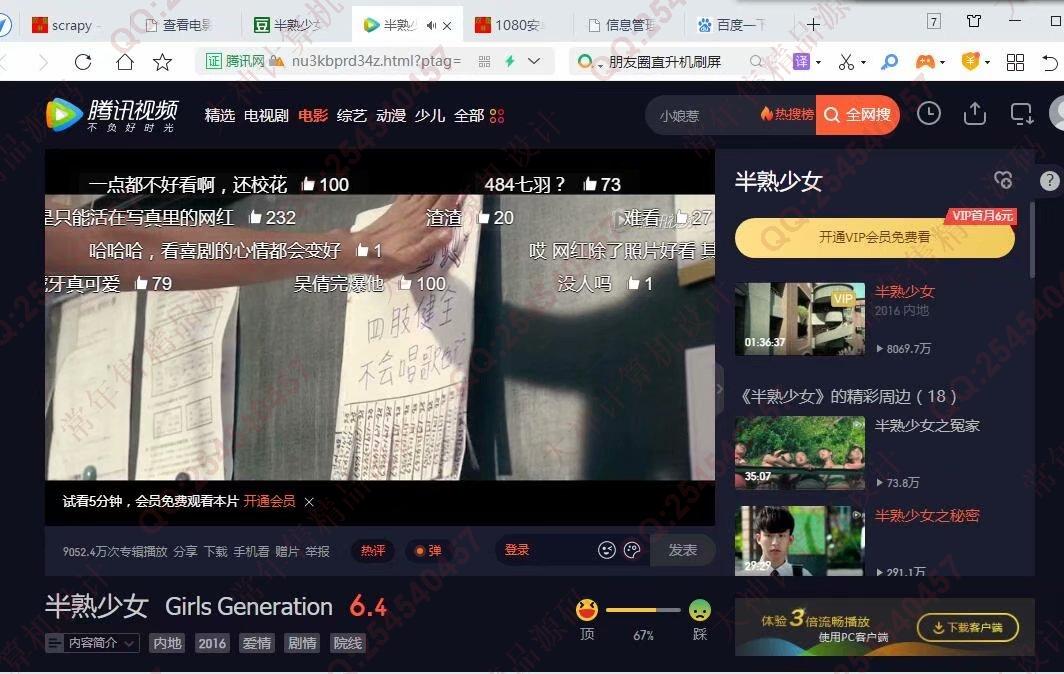
照片名称:11电影在线播放地址打开效果
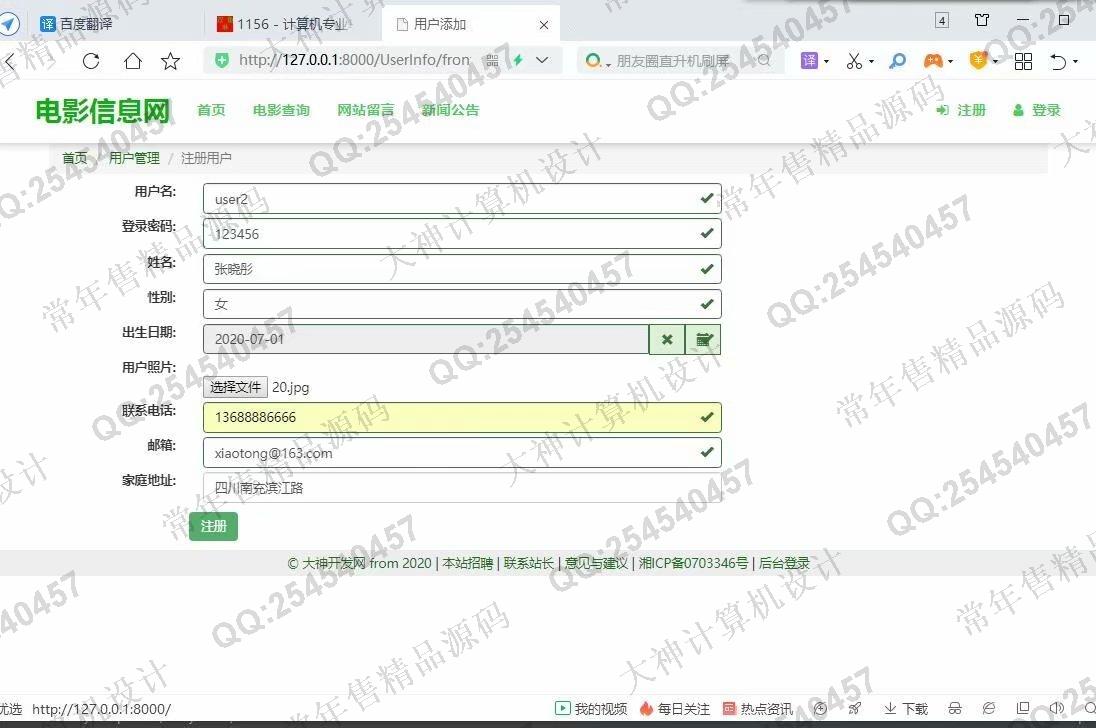
照片名称:12前台网站用户注册
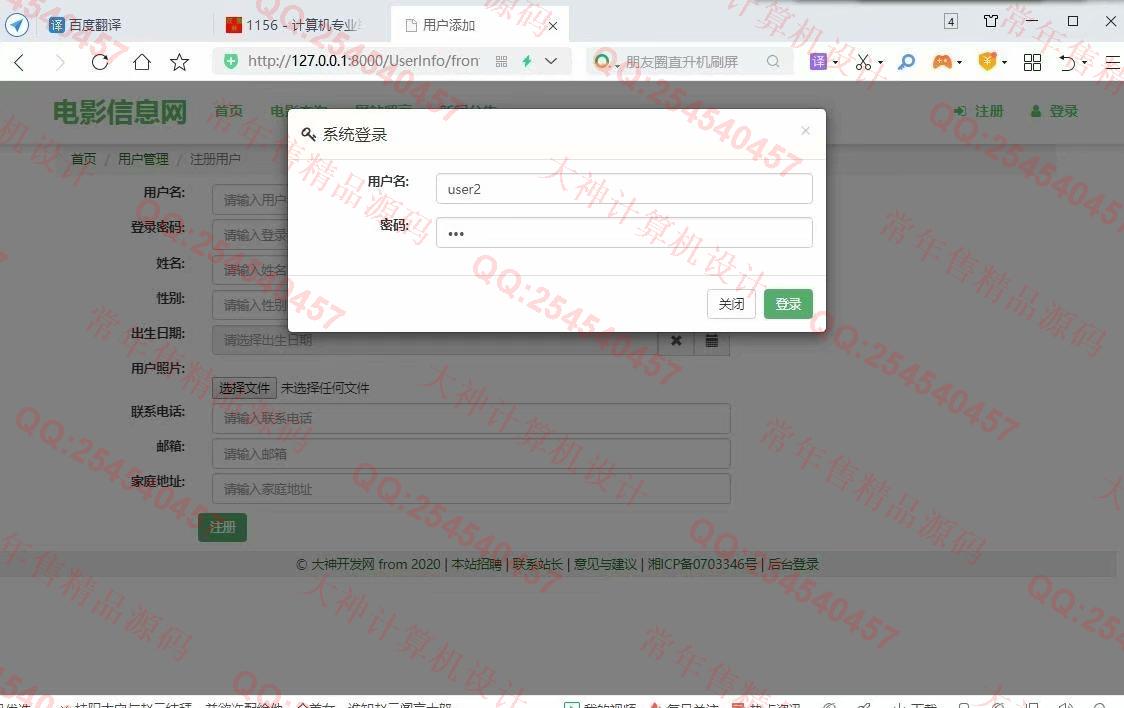
照片名称:13前台用户登录
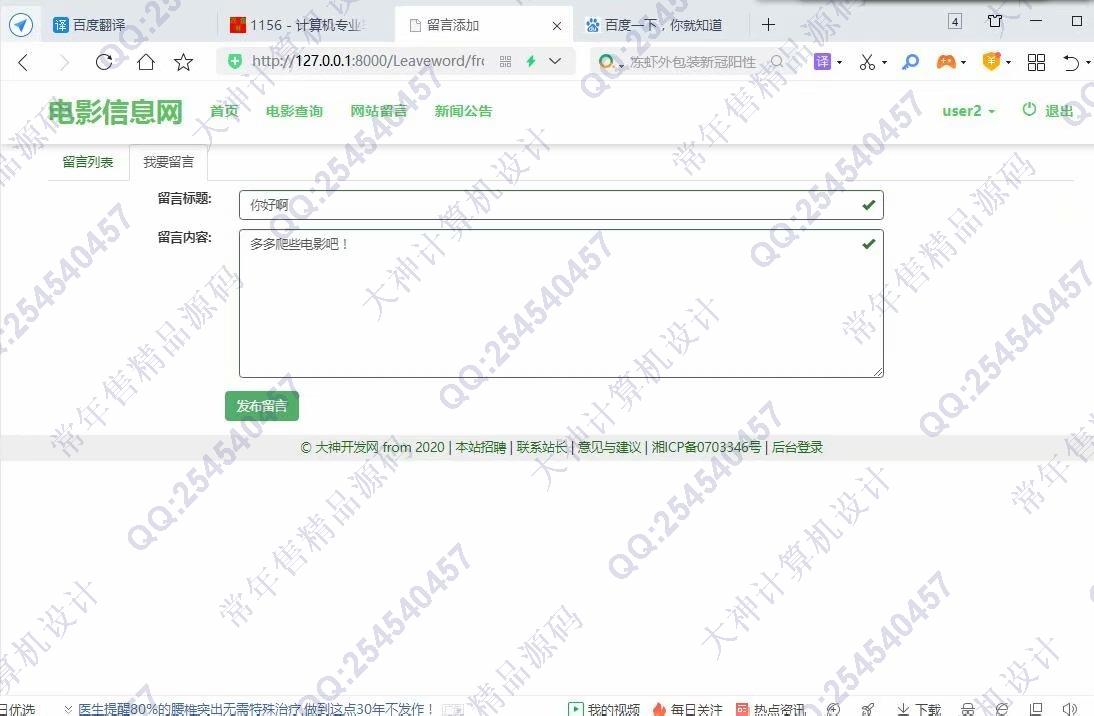
照片名称:14前台用户发布留言
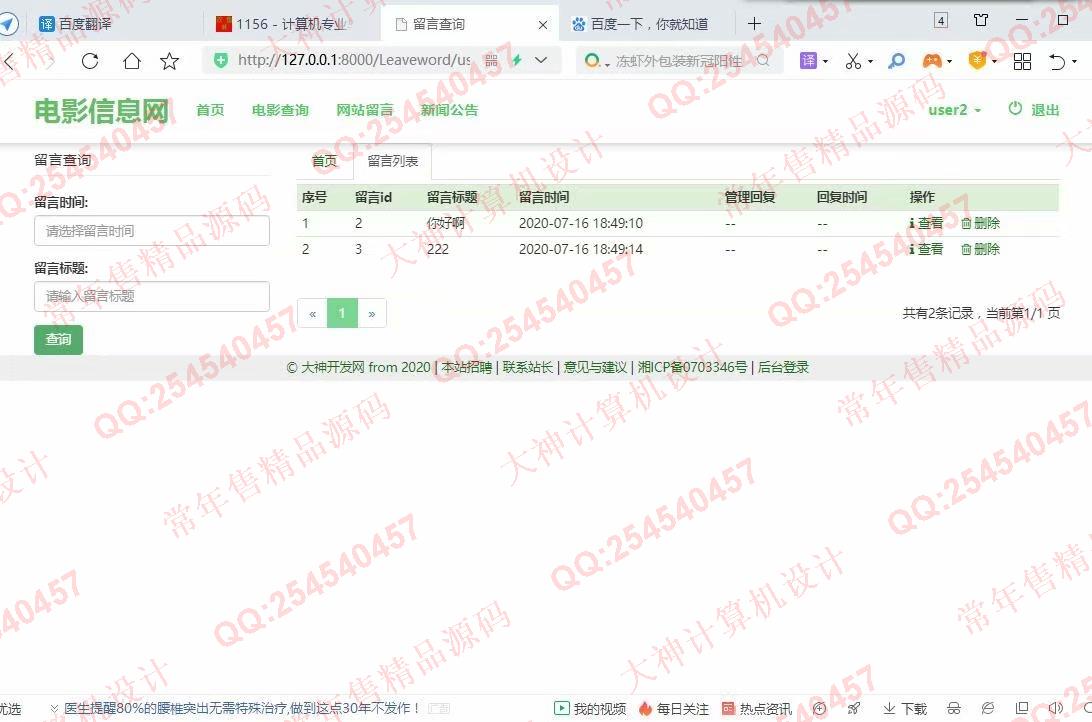
照片名称:15前台用户管理自己的留言

照片名称:16前台新闻公告查询
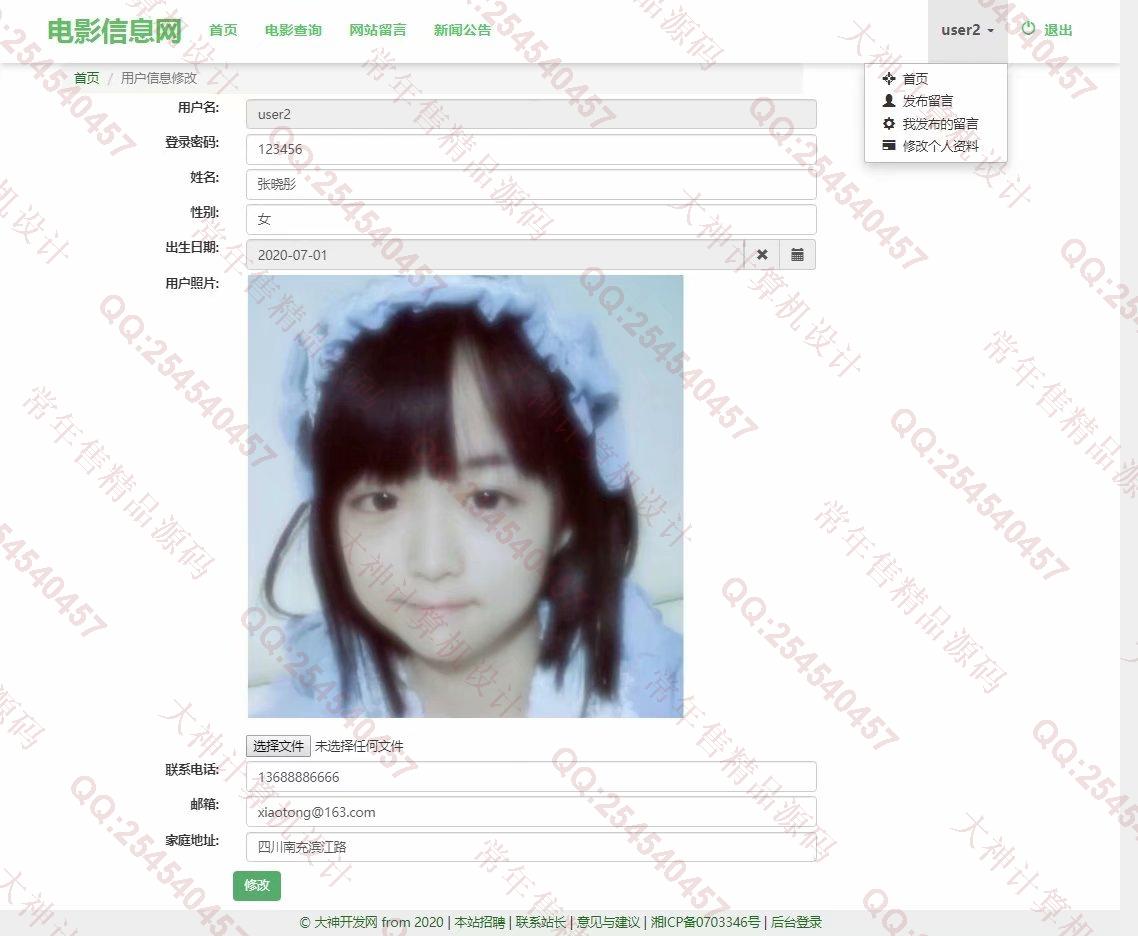
照片名称:17前台用户修改个人信息
照片名称:18后台管理员登录
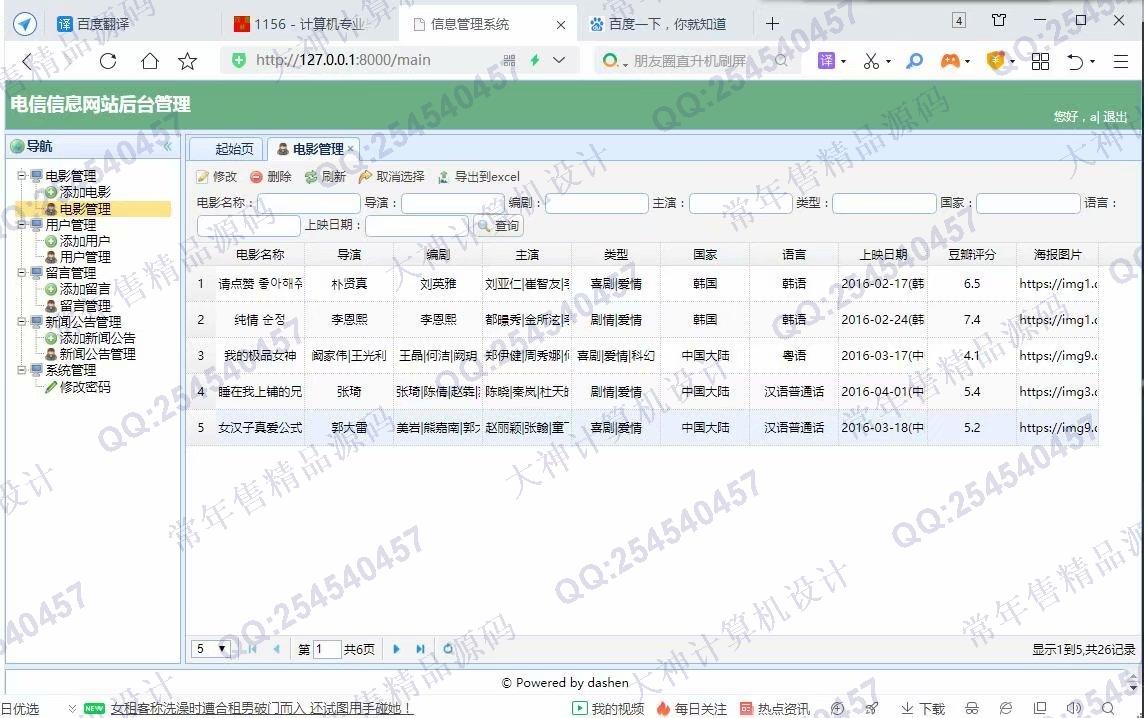
照片名称:19后台电影信息查询管理
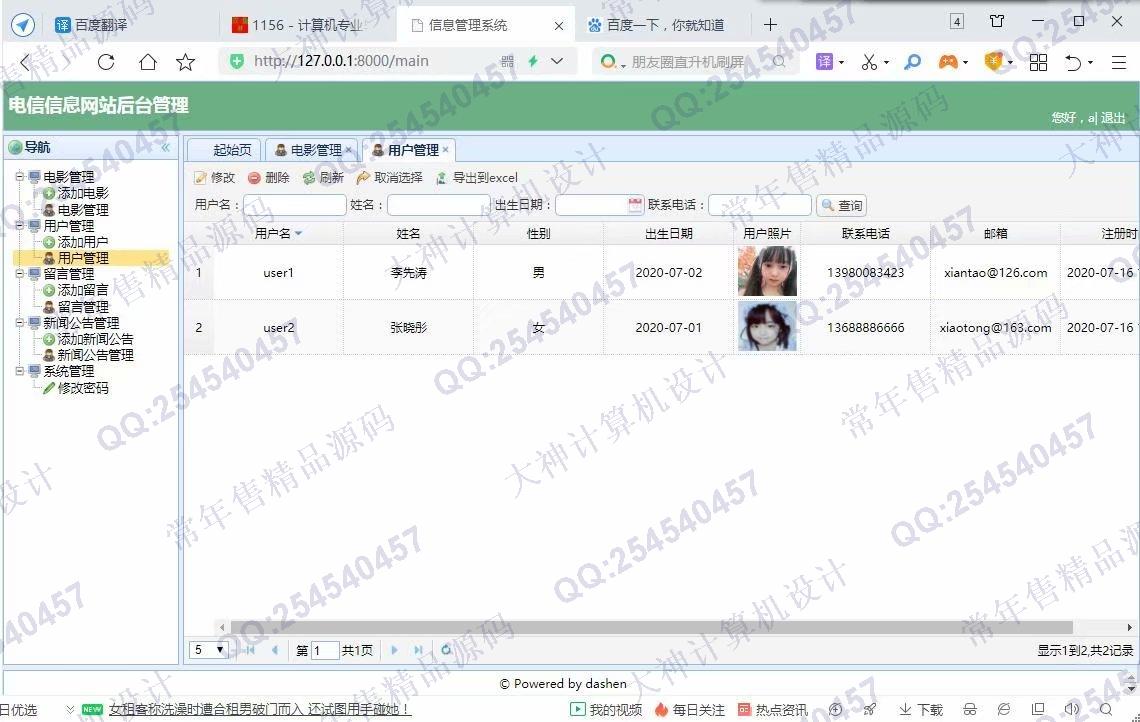
照片名称:20注册用户信息管理
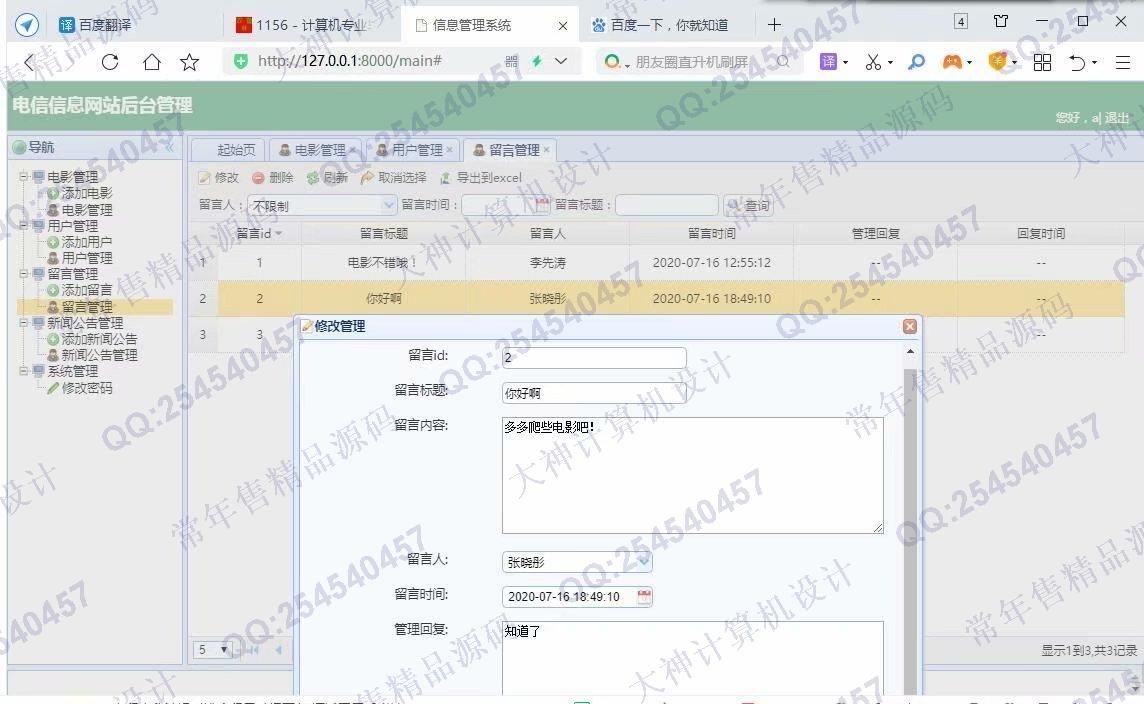
照片名称:21网站留言回复管理
照片名称:22网站新闻公告发布
以上是本计算机毕业源码设计介绍,若对此项目感兴趣,请联系QQ:254540457
